local-interpretation-for-gbdt
GBDT样本预测局部解释性
View the Project on GitHub Ulti-Dreisteine/local-interpretation-for-gbdt
GBDT模型的局部解释
Local Model Interpretation for GBDT
算法背景
集成树方法如随机森林(Random Forest,RF)、梯度提升树(Gradient Boosing Decision Tree, GBDT)及其变种XGBoost等由于其良好的拟合能力和模型解释性,在金融、医学统计等诸多领域有广泛的应用。
一般的RF、GBDT或XGBoost模型学习完毕后,模型会基于样本集得出各特征的重要性分数feature_importances,但是这种分数是基于样本整体得出的,模型学习完毕后各特征分数便已固定。而在实际应用中我们还关心模型对于特定个体在各个特征上的重要性评分分布,即局部解释性(local interpretation),以便于针对个体提出更精准的方案和建议。参考文献[1]中便提出了一种可以实现该目标的算法。
算法简介
决策树:
- 初始化父节点;
- 在所有特征中搜索最大增益对应的分裂特征和分裂值;
- 执行分裂;
- 重复2~3直至满足终止条件;
GBDT:
-
初始化:
\[s = 0\] \[f_0(x) = 0\] -
对于所有样本$x$,计算损失函数$r_s$:
\[r_s = L\left(y, \sum_{i=0}^{s}{f_i(x)} \right)\] -
对残差$r_s$进行拟合,得到回归树$h_s$;
-
更新:
\[f_{s+1}(x)=f_s(x)+h_s(x)\] \[s = s + 1\] -
重复以上步骤2~4,直至满足终止条件;
其中,GBDT的损失函数$L$可以有以下选择:
| Settings | Loss Function | Negative Gradient |
|---|---|---|
| LS | $\frac{1}{2}\left(y_i - f(x_i)\right)^2$ | $y_i - f(x_i)$ |
| LAD | $|y_i - f(x_i)|$ | ${\rm sign} (y_i - f(x_i))$ |
| XGB | $\sum_{i=1}^{n} {[l(y_i,\hat y^{t-1}) + g_if_t(x_i) + \frac{1}{2}h_if_t^2(x_i)] + \Omega(f_t)}$ | / |
| Absolute | $\vert y_i - f(x_i)\vert$ | / |
| Huber | \(\begin{aligned} \frac{1}{2}(y_i - f(x_i))^2, \quad \vert y_i -f(x_i) \vert \leq \delta \\ \delta(\vert y_i - f(x_i) \vert \frac{\sigma}{2}), \quad \vert y_i - f(x_i) \vert > \delta \\ \end{aligned}\) | / |
注意:
- 基于残差的GBDT在解决回归问题上不是好的选择,因为对异常值过于敏感,一般回归类损失函数会选用绝对损失函数或者huber损失函数来代替平方损失函数[2]。
GBDT在对每个基学习器回归的过程中都希望损失函数最小化,设损失函数为:
\[L = \frac{1}{2}\left(y_i - f(x_i)\right)^2\]则1阶导数为:
\[\frac{\partial L}{\partial f(x_i)} = f(x_i) - y_i\]此时残差与负梯度一致:
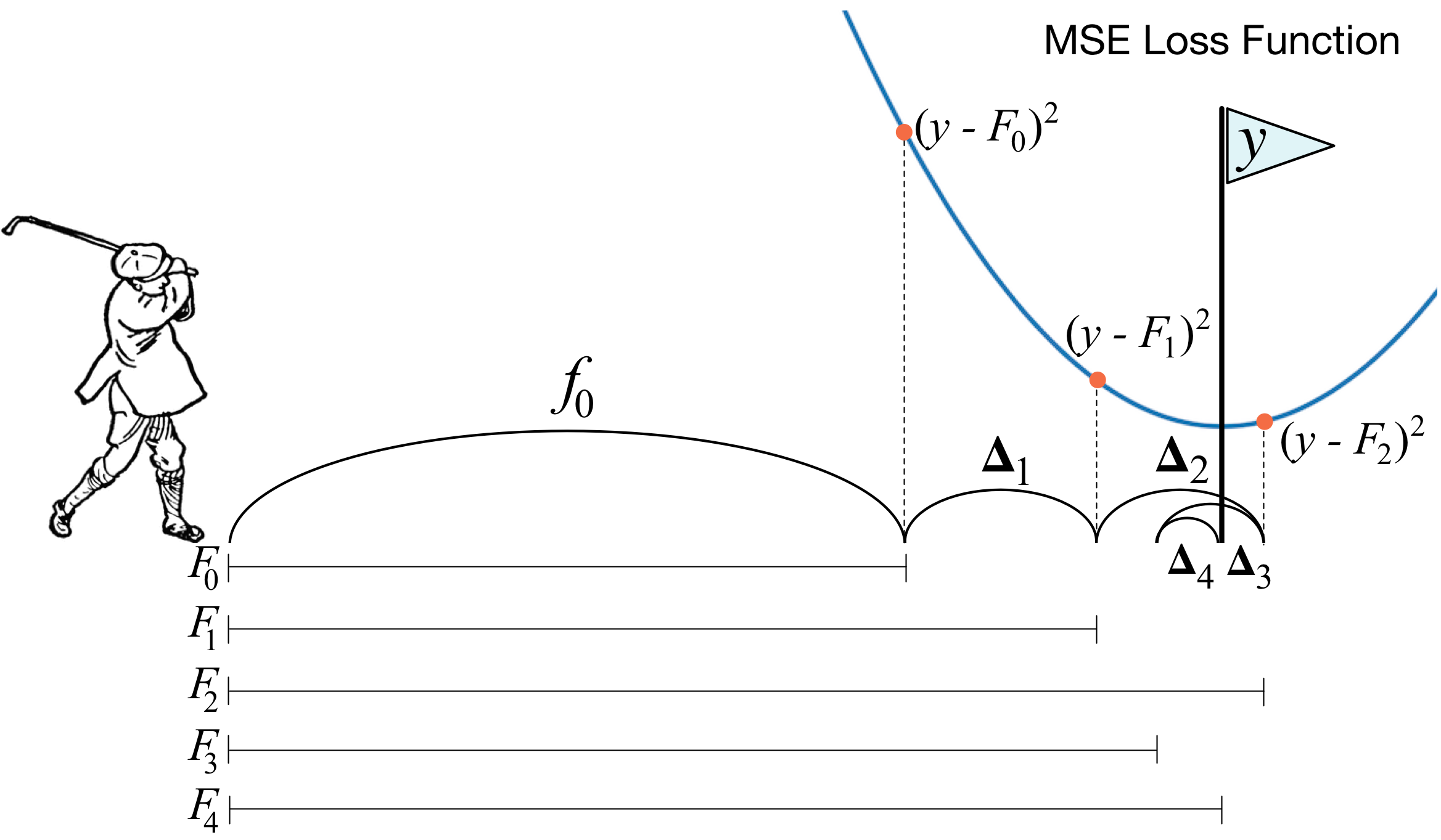
\[y_i - f(x_i) = - \frac{\partial L}{\partial f(x_i)}\]GBDT的局部解释
假设我们基于样本集$X$对目标$y$进行回归得到GBDT模型$f$,其中$X$有$N$个样本,$m$个特征,模型$f$中的$k$个基学习器可表示为${f_0, f_1, f_2, …, f_k}$,则有:
\[{\hat y} = \sum_{i=0}^{k}{f_i(x)}\]其中${\hat y}$即为GBDT预测的结果。为了对模型的个体预测进行解释,文献中参考随机森林的办法引入特征贡献(feature contribution)这一概念,计算公式如下:
\[LI_f^c = \left\{ \begin{aligned} &Y_{\rm mean}^c - Y_{\rm mean}^p, \quad \text{if split is performed on feature } \textit{f}\\ &0, \quad \quad \quad \quad \quad \quad \text{otherwise} \end{aligned} \right.\]式中$LI_f^n$表示特征$f$在节点$n$上的局部增益,$Y_{\rm mean}^n$表示节点$n$中的正样本比例。若父节点$S_p$分裂为$S_{c1}$和$S_{c2}$两个子节点,则父节点的分数为:
\[Y_p = \frac{N_{c1} \times Y_{c1} + N_{c2} \times Y_{c2}}{N_{c1} + N_{c2}}\]式中$N_{c1}、N_{c2}$分别表示落入两个子代节点$S_{c1}$和$S_{c2}$的样本数。
对于随机森林,在一棵树$t$中,特征$f$对于样本个体$i$的贡献值为:
\[FC_{i,t}^f = \sum_{c \in path(i)}{LI_f^c}\]在整个随机森林中,特征$f$对于样本个体$i$的贡献值为:
\[FC_{i}^f = \frac{1}{k} \sum_{t=1}^{k}{FC_{i,t}^{f}}\]对于GBDT,特征$f$对于样本个体$i$贡献的计算公式需要修改为:
\[FC_{i}^f = \sum_{t=1}^{k}{w_t \cdot FC_{i,t}^{f}}\]式中$w_t$为基学习器$t$在整个GBDT中所占的权重,可以通过上述损失函数$L$表格获得。
参考文献
- W.J. Fang, J. Zhou, etc.: Unpack Local Model Interpretation for GBDT, 2018
- https://zhuanlan.zhihu.com/p/29765582 “一文理解GBDT”
联系方式
- Email:dreisteine262@163.com